1. 제약 조건

-- 테이블 생성과 제약 조건
-- primary key(테이블의 고유 키, 중복 X, null 허용 X)
-- unique(중복 X)
-- not null(null을 허용하지 않음)
-- foreign key(참조하는 테이블의 pk를 저장하는 컬럼, 참조테이블의 pk에 없다면 등록 x, null 허용)
-- check( 정의된 형식만 저장되도록 허용)
--------------------------------------------------------------------------------
select * from user_constraints;
-- 열레벨 제약
create table dept2 (
dept_no number(2) constraint dept2_no_pk primary key, -- 제약조건은 constraint(이름 지정할 때 씀)
dept_name varchar2(15) constraint dept2_name_nn not null,
loca number(4) constraint dept2_loca_locaid_fk references locations(location_id), --fk는 references로 연결
dept_date date default sysdate, -- default 내가 값을 넣지 않았을 때 기본으로 지정되는 값
dept_bonus number(10) default 0,
dept_phone varchar2(20) constraint dept2_phone_uk unique,
dept_gender char(1) constraint dept2_gender_ck check(dept_gender in ('m', 'f') ) -- check()안에 조건(where이랑 똑같음)
);
desc locations; -- location_id가 pk
-- 열레벨 제약(constraints 생략 가능)
drop table dept2;
create table dept2 (
dept_no number(2) primary key, -- 제약조건은 constraint(이름 지정할 때 씀)
dept_name varchar2(15) not null,
loca number(4) references locations(location_id), --fk는 references로 연결
dept_date date default sysdate, -- default 내가 값을 넣지 않았을 때 기본으로 지정되는 값
dept_bonus number(10) default 0,
dept_phone varchar2(20) unique,
dept_gender char(1) check(dept_gender in ('m', 'f') ) -- check()안에 조건(where이랑 똑같음)
);
-- 테이블 레벨(not null만 열레벨로 사용), 나머지는 아래쪽에 명시
drop table dept2;
create table dept2 (
dept_no number(2),
dept_name varchar2(15) not null,
loca number(4),
dept_date date default sysdate,
dept_bonus number(10) default 0,
dept_phone varchar2(20),
dept_gender char(1),
constraint dept2_no_pk primary key (dept_no /*, dept_name*/), -- 슈퍼키
constraint dept2_loca_locaid_fk foreign key(loca) references locations(location_id),
constraint dept2_phone_uk unique (dept_phone),
constraint dept2_gender_ck check(dept_gender in ('m', 'f') ) -- 얘는 안에 들어가있으니까
);
-- 제약 조건의 위배
desc employees;
-- 개체 무결성 위배(null, 중복 값이 pk에 들어갈 수 없음)
insert into employees(employee_id, last_name, email, hire_date, job_id)
values(100, 'test', 'test', sysdate, 'test'); -- employee_id가 이미 있음
-- 참조 무결성 위배(참조하는 테이블의 pk로 존재해야 fk에 들어갈 수 있음)
insert into employees(employee_id, last_name, email, hire_date, job_id, department_id)
values(501, 'test', 'test', sysdate, 'test', 5);
-- 도메인 무결성 위배(컬럼에 정의된 값만 들어갈 수 있음)
insert into employees(employee_id, last_name, email, hire_date, job_id, salary)
values(501, 'test', 'test', sysdate, 'test', -10);
--------------------------------------------------------------------------------
-- 제약 조건 추가, 삭제(변경 불가)
drop table dept2;
create table dept2 (
dept_no number(2),
dept_name varchar2(15),
loca number(4),
dept_date date default sysdate, --default: 기본값
dept_bonus number(10) default 0,
dept_phone varchar2(20),
dept_gender char(1)
);
-- 테이블 레벨과 유사
-- pk 추가
alter table dept2 add constraints dept_no_pk primary (dept_no);
-- fk 추가
alter table dept2 add constraints dept_loca_fk foreign key (loca) references locations(location_id);
-- unique 추가
alter table dept2 add constraints dept_name_uk unique (dept_phone);
-- check 추가
alter table dept2 add constraints dept_gender_ck check (dept_gender in ('m', 'f') );
-- not null - 컬럼 변경문으로
alter table dept2 modify dept_name varchar2(15) not null;
-- 제약 조건을 삭제(제약 조건명)
alter table dept2 drop constraints dept_loca_fk;
1.2) 마우스로 제약조건

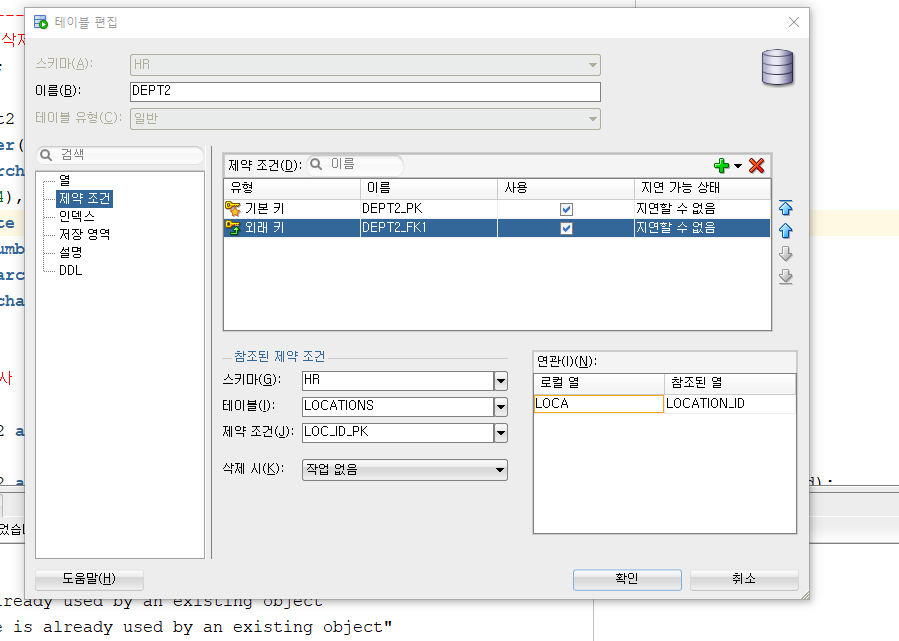


1.3) 예제
-- 예제
-- 문제 1.
-- 다음과 같은 테이블을 생성하고 데이터를 insert하세요 (커밋)
-- 조건) M_NAME 는 가변문자형, 널값을 허용하지 않음
-- 조건) M_NUM 은 숫자형, 이름(mem_memnum_pk) primary key
-- 조건) REG_DATE 는 날짜형, 널값을 허용하지 않음, 이름:(mem_regdate_uk) UNIQUE키
-- 조건) GENDER 가변문자형
-- 조건) LOCA 숫자형, 이름:(mem_loca_loc_locid_fk) foreign key – 참조 locations테이블(location_id)
--문제 2.
-- MEMBERS테이블과 LOCATIONS테이블을 INNER JOIN 하고 m_name, m_mum, street_address, location_id
-- 컬럼만 조회
-- m_num기준으로 오름차순 조회
create table members (
m_name varchar2(20) not null,
m_num number(3) constraint mem_memnum_pk primary key,
reg_date date not null constraint mem_regdate_uk unique, -- 날짜는 동일한 날짜가 나올 수도 있어서 unique키로 하면 안됨
gender varchar2(5),
loca number(4) constraint mem_loca_loc_locid_fk references locations(location_id)
-- constraint mem_memnum_pk primary key (컬럼)
-- constraint mem_regdate_uk unique (컬럼)
-- constraint mem_loca_loc_locid_fk foreign key (컬럼) references locations(location_id)
);
insert into members values ('AAA', 1, '2018-07-01', 'm', 1800); -- 마지막은 location 컬럼의 pk만 들어갈 수 있음(있어야만 넣을 수 있음)
insert into members values ('BBB', 2, '2018-07-02', 'f', 1900);
insert into members values ('CCC', 3, '2018-07-03', 'm', 2000);
insert into members values ('DDD', 4, sysdate, 'm', 2000);
select m_name, m_num, to_char(reg_date, 'YYYY-MM-DD'), gender, loca from members;
select * from locations;
select * from members;
select m_name, m_num, street_address, location_id
from members m
join locations l
on m.loca = l.location_id -- location_id가 존재하지 않으니까 loca
order by m_num asc;
2. 뷰(view)
--
-- view는 제한적인 자료만 보기 위해 사용할 수 있는 가상테이블의 개념입니다.
-- 뷰는 기본테이블로 유도도니 가상 테이블 이기 때문에 필요한 컬럼만 저장해 두면 관리가 용이해집니다.
-- 뷰는 가상테이블로 실제 데이터가 물리적으로 저장된 형태는 아닙니다.
-- 뷰를 통해서 데이터에 접근하면 원본 데이터는 안전하게 보호 할 수 있습니다.
-- 안쓰더라도 상관 없음
select * from emp_details_view;
-- 단순 뷰
-- 뷰의 컬럼 이름은 함수 같은 가상 표현식이면 안됩니다.
create or replace view view_emp
as (select employee_id,
first_name || ' ' || last_name as name, -- 여기가 엘리어스로 이름이 들어가줘야 함
job_id,
salary
from employees
where department_id = 60
);
select * from view_emp;
-- 복합 뷰
-- 여러 테이블을 조인하여 필요한 데이터만 저장하고 빠른 확인을 위해서 사용
create or replace view view_emp_dept_job
as (select
e.employee_id,
first_name || ' ' || last_name as name, -- 여기가 엘리어스로 이름이 들어가줘야 함
d.department_name,
j.job_title
from employees e
left outer join departments d
on e.department_id = d.department_id
left outer join jobs j
on e.job_id = j.job_id)
order by employee_id;
select * from view_emp_dept_job;
-- 뷰의 수정(동일이름으로 만들면 수정됩니다)
create or replace view view_emp_dept_job
as (select
e.employee_id,
first_name || ' ' || last_name as name, -- 여기가 엘리어스로 이름이 들어가줘야 함
e.salary, -- 추가
d.department_name,
j.job_title
from employees e
left outer join departments d
on e.department_id = d.department_id
left outer join jobs j
on e.job_id = j.job_id)
order by employee_id;
select * from view_emp_dept_job;
-- 복합 뷰로 생성 하면 데이터를 손쉽게 조회 가능합니다.
-- job_title 별 salary 평균
select job_title, avg(salary) as 평균
from (select *
from employees e
left join jobs j on e.job_id = j.job_id)
group by job_title
order by 평균;
select j.job_title, avg(salary) as 평균
from employees e
left join jobs j
on e.job_id = j.job_id
group by job_title
order by 평균;
-- view를 통한 조회
select job_title, avg(salary) as 평균
from view_emp_dept_job
group by job_title;
-- 뷰의 삭제
drop view 뷰이름;
--------------------------------------------------------------------------------
desc view_emp_dept_job;
-- 뷰를 통한 dml은 제한이 많습니다.
-- name은 물리적 테이블에 존재하지 않아서 허용하지 않음
-- 가상열 컬럼이 있다면 허용되지 않음.
insert into view_emp_dept_job(name, employee_id) values('xxx', 300);
-- 원본 테이블의 null을 허용하지 않는 경우도 안됩니다.
insert into view_emp_dept_job(employee_id, salary) values(300, 10000);
-- join된 뷰의 경우도 허용되지 않습니다.
insert into view_emp_dept_job(employee_id, job_title) values(300, 'xxx');
--------------------------------------------------------------------------------
-- 뷰의 옵션
-- with check option - 조건 컬럼 제약(컬럼 변경 불가)
create or replace view view_emp_test
as (select employee_id, first_name, department_id
from employees
where department_id In (60,70,80)
)
with check option;
select * from view_emp_test;
-- with read only - 읽기 전용 뷰(조회만 가능)
create or replace view view_emp_test
as (select employee_id, first_name, department_id
from employees
where department_id In (60,70,80)
)
with read only;
select * from view_emp_test;
3. 시퀀스
-- 시퀀스(순차적으로 증가하는 값 - pk에 많이 사용됩니다.)
select * from user_sequences;
-- 테이블
create table dept3 (
dept_no number(2) primary key, -- 시퀀스 적용 하려면 number
dept_name varchar2(20),
loca varchar2(20),
dept_date date
);
-- 시퀀스 생성
create SEQUENCE dept3_seq
INCREMENT by 1 -- 콤마 없음
start with 1
MAXVALUE 10
MINVALUE 1 -- 1미만으로 떨어질 수 없음
NOCYCLE
NOCACHE;
-- 시퀀스 삭제
drop sequence dept3_seq;
-- 시퀀스 생성(기본값으로 생성)
create sequence dept3_seq nocache;
-- 시퀀스 사용 currval, nextval
select dept3_seq.currval from dual; -- currval는 nextval 한번 이후에 사용 가능
select dept3_seq.nextval from dual; -- 후진 없음, 10번까지 점핑
insert into dept3(dept_no, dept_name, loca, dept_date)
values(dept3_seq.nextval, 'test', 'test', sysdate); -- 맨앞에 dept3~ 쓰면 pk는 신경쓰지 않아도 됨
select * from dept3_seq;
-- 시퀀스 수정
ALTER SEQUENCE dept3_seq NOCACHE;
ALTER SEQUENCE dept3_seq MAXVALUE 1000;
ALTER SEQUENCE dept3_seq INCREMENT by 10;
-- 시퀀스가 테이블에서 사용되고 있다면 drop 하면 안됩니다.
-- 시퀀스값을 초기화 하려면 ?
-- 1. 현재 시퀀스 확인
select dept3_seq.currval from dual;
-- 2. 증가값을 - 현재 시퀀스
alter SEQUENCE dept3_seq minvalue 0;
alter sequence dept3_seq INCREMENT by -130;
-- 3. nextval로 실행
select dept3_seq.nextval from dual;
-- 4. 증가값을 1로 변경
alter sequence dept3_seq INCREMENT by 1;
-- 5. 실행
select dept3_seq.nextval from dual;
-- 시퀀스 사용의 응용
create table dept4(
dept_no varchar2(30) primary key,
dept_name varchar2(30)
);
create sequence dept4_seq nocache;
-- LPAD('값', '맥스길이', '채울값')을 이용해서 pk에 적용하는 값을 (년-0000시퀀스) 형태로 insert
select * from dept4;
select to_char(sysdate, 'yyyymm') || lpad(seq.nextval, 5, '0') as dept_no from dual;
select concat( to_char(sysdate, 'YYYY'), LPAD(dept4_seq.nextval, 5, '0') ) from dual;
insert into dept4 values (to_char(sysdate, 'YYYY') || lpad(dept4_seq.nextval, 5, '0'), 'test');'TIL > SQL' 카테고리의 다른 글
| day35-DB: sql (0) | 2022.11.18 |
|---|---|
| day34-DB: sql (0) | 2022.11.17 |
| day32-DB: sql (0) | 2022.11.15 |
| day31-DB: sql (0) | 2022.11.14 |
| day30-DB: sql (0) | 2022.11.11 |
